Tecnologie e Progettazione di Sistemi Informatici - Terzo anno
A.S. 2021-2022
Istituto di Istruzione Superiore G. Marconi
Prof. Claudio Capobianco
HTML&CSS
In questo capitolo impareremo come sviluppare delle pagine web usando solo HTML & CSS.
Internet & Web
Prima di cominciare con lo studio dell'HTML, cerchiamo di capire un po' il contesto in cui è nato e si è sviluppato.
Quando parliamo di web stiamo parlando di un insieme di tecnologie specifiche, quelle appunto definite dal consorzio del "World Wide Web", abbreviato in w3. Il sito ufficiale del consorzio e www.w3.org.
Ma andiamo con ordine: il web è un servizio che si appoggia alla rete Internet per funzionare. Le due cose non devono essere confuse!
Internet: una rete di computer globale
Negli anni '60 del secolo scorso c'è stata un'enorme diffusione dei calcolatori elettronici soprattutto presso centri di ricerca universitaria ed istituzioni pubbliche. Il problema di connettere tra di loro tutti questi computer era diventata urgente, e vari standard erano nati per risolvere questo problema.
La soluzione che poi ha preso il sopravvento è stata quella ideata da Vinton Gray Cerf e Robert Kahn nel 1972 circa, mentre lavoravano presso il DARPA (Agenzia per i Progetti di ricerca avanzata per la Difesa), in America, hanno messo le basi per questa tecnologia ed i relativi protocolli.

L'idea è stata quella di assegnare ad ogni macchina un indirizzo, chiamato IP Address, (IP sta per Internet Protocol) formato da 4 byte, che lo identifica univocamente all'interno di una sottorete. All'indirizzo IP deve sempre essere associato un altro numero, chiamato maschera di sottorete (subnet mask), anch'esso di 4 byte, che definisce la grandezza della sottorete in cui ci troviamo. Le reti sono connesse tra di loro da dei dispositivi di rete dedicate, tipicamente dei router (instradatori).
Uno dei motivi per cui Internet ha avuto una così grande diffusione è stata la convinzione dei fondatori che le tecnologie alla base della comunicazione tra i computer dovesse essere libera ed aperta, ovvero tutti potessero usarla senza pagare un costo di licenza e contribuire al suo miglioramento. A tal fine, per esempio, nel 1986 fu istituita la Internet Engineering Task Force (IETF), un organismo internazionale caratterizzato da forti principi di apertura e condivisione. L'IETF usa il sistema delle RFC per la discussione e l'approvazione dei propri standard, che prevede la discussione e l'approvazione. Nel 2005 Vint Cerf e Bob Kahn hanno ricevuto la Medaglia Presidenziale per la libertà per il loro contributo alla nascita di Internet.
Una nota sull'uso della parola "Internet": tecnicamente, una qualsiasi rete di computer connessi tra di loro con indirizzi IP è una rete Internet. Tuttavia, nell'uso quotidiano usiamo questa parola per indicare la rete globale di computer. In questo testo si specificherà "rete Internet globale" quando necessario per evitare fraintendimenti.
Web
Il World Wide Web è nato nel 1989 sotto la guida del londinese Tim Berners-Lee. A quel tempo, Berners-Lee lavorava presso il CERN di Ginevra, un centro di ricerca internazionale. Come i suoi colleghi, si trovava ad affrontare il problema di reperire le informazioni su Internet; gli strumenti che a quel tempo aveva a disposizione erano protocolli come FTP, SSH, SCP che non permettevano una facile consultazione delle risorse.
L'idea di Berners-Lee per risolvere il problema è stato quello di creare delle pagine con uno stile (corsivo, grassetto, titolo, ...) che puntassero a delle risorse (immagini, file, altre pagine, ...). In questo modo si creava una rete di pagine e risorse che somigliava appunto ad una rete.
Per lo stile delle pagine inventò lo standard HyperText Markup Language (HTML), per il protocollo di comunicazione creò l'Hypertext Transfer Protocol (HTTP) e per identificare univocamente una risorsa sul web ideò l'Uniform Resource Locator (URL).
Nel 1994 Tim Burners-Lee fonda il w3consortium (w3c) con lo scopo di standardizzare le nuove tecnologie emergenti per il World Wide Web.
Fin dai primi anni di fondazione del w3c fu chiaro che per far crescere in maniera organica il web, il solo formato HTML non era sufficiente. Sono state create quindi un insieme di tre tecnologie, ognuna con un compito diverso che si coordinano fra loro:
- le pagine html, che definiscono la struttura della pagina
- i fogli di stile css, che definiscono come la pagina deve essere visualizzata
- i file js, ovvero JavaScript, che definiscono il comportamento dinamico del sito
Nei prossimi capitoli affronteremo nel dettaglio i primi due: HTML e CSS.
HTML
Breve storia
Tutta la storia del web ebbe inizio con delle pagine rappresentate da un singolo file con estensione .html. Questo file comprendeva tutte le informazioni necessarie per visualizzare la pagina. Nei primi anni '90 del secolo scorso, le pagine erano statiche e lo stile per visualizzare gli elementi non era distinto dalle altre informazioni della pagina.
Tim Berners Lee dal 1989 al 1993 lavorò in team per proporre le nuove tecnologie web come uno standard di Internet, e finalmente nel 1993 divenne a tutti gli effetti uno standard IETF (Internet Engineering Task Force). Nell'ottobre 1994 Berners-Lee fonda il World Wide Web Consortium (W3C) al Massachusetts Institute of Technology di Boston.
Il lavoro del consorzio continua rilasciando nuove versioni a ritmo serrato, introducendo per esempio il CSS nel 1996, fino alla versione 4.01 del 2001. A questo punto si voleva dare una grossa svolta alle tecnologie web, abbandonando l'HTML a favore di XML, un formato più ricco ma anche molto più rigido e non retrocompatibile.
Diverse grandi aziende, tra cui Apple, Mozilla, Opera e Google, non erano d'accordo con le decisioni del w3c e fondarono un nuovo gruppo di lavoro chiamato WHATWG (Web Hypertext Application Technology Working Group). Cominciò così una collaborazione/scontro tra w3c e WHATWG che arrivò ad approvare lo standard HTML5 nel 2014 (14 anni dopo la versione HTML4!), che sostanzialmente ha recepito la linea del WHATWG che conosciamo oggi. La diatriba si è conclusa definitivamente nel 2019 con la cessione dell'authority sullo standard da parte del w3c a favore di WHATWG (vedi qui per maggiori dettagli).
È importante sapere anche che HTML5 è considerato l'ultima versione di HTML, perché è considerato un Living standard, quindi non ha più rilasci di versione congelate ma è in continua evoluzione.
Cosa significa "struttura" di una pagina?
Abbiamo detto che l'HTML definisce la "struttura" della pagina. Ma cosa significa esattamente?
In poche parole, significa che l'HTML esprime il significato della pagina, non la sua presentazione. La stessa pagina può essere visualizzata in modo diverso in dispositivi diversi (desktop, smartphone, tablet, smartTV, smart watch, realtà virtuale...) o addirittura letta da dispositivi come Google Home o Alexa.
Inoltre, se diamo un senso agli elementi della pagina, e li organizziamo in maniera opportuna, possiamo anche permettere ai browser di elaborare la pagina ed estrarre informazioni utili per noi. Per esempio potremmo chiedere al browser quali sono le voci del menu, o di andare alla sezione successiva.
Come ultima cosa (ma non meno importante), i software dei vari motori di ricerca o i web spider possono interpretare con più esattezza la pagina ed estrarre informazioni utili da usare in altri siti o servizi.
Esempi di struttura
Prendiamo ad esempio il seguente sito, che tratta di un bellissimo linguaggio di programmazione: Rust.

Proviamo ad analizzare la struttura della pagina. Notiamo che nella parte alta della pagina c'è un'intestazione che contiene informazioni particolarmente importanti, come ad esempio il logo e un menù di navigazione, per saltare rapidamente alle diverse sezioni della pagina. Nella parte più a destra dell'intestazione c'è un menù a tendina per scegliere la lingua preferita.
Subito sotto, c'è una sezione in cui ci sono le informazioni più importanti su cui si vuole attirare l'attenzione del vistatore: il nome del sito, una breve descrizione (tag line), un bottoncione colorato per cominciare e sotto il bottone si specifica l'ultima versione del linguaggio.
Scorrendo la pagina, si trovano altre sezioni con altre informazioni utili, fino ad arrivare in fondo in cui troviamo un footer con le informazioni legali, alcuni link per approfondire e le icone per i social network.
Ogni singolo elemento della pagina è identificato nella pagina HTML sorgente con un nome che ne identifica il significato, il che rende molto più semplice visualizzarlo ad esempio per un cellulare, come nella figura di seguito.

Organizzazione degli elementi della pagina
Un'altra cosa importante da capire a questo momento è come gli elementi di una pagina HTML si relazionano tra loro. Gli elementi sono organizzati con una struttura ad albero, o a scatole cinesi, in cui si parte da un elemento base a cui si agganciano tutti gli altri.
Nella metafora ad albero, l'elemento base viene chiamato radice (anche se forse sarebbe più corretto chiamarlo tronco), da cui partono vari rami che finiscono con delle foglie. Molto spesso l'albero viene rappresentato rovesciato, con il tronco in alto.
<body> <-- radice
/ \
<nav> <h1> <-- rami o foglie
/ \
<img> <ul> <-- foglie
Nella metafora a scatole cinesi, c'è una scatola esterna che contiene una o più scatole al suo interno, che a loro volta possono contenere altre scatole, e così via finché non arriviamo alle scatole più interne che saranno vuote.

Riprendendo l'esempio della pagina del linguaggio di programmazione Rust ed usando la metafora delle scatole, possiamo vedere che è stata organizzata nel seguente modo.

Questa operazione di suddividere la pagina web in sottoparti viene chiamata cutting (taglio) della pagina, ed è un'operazione che si svolge a dopo la fase di design e prima di quella di implementazione vera e propria.
Altri esempi


La mia prima pagina
In questo tutorial, oltre a creare una pagina vogliamo mettere le basi per un progetto completo.
Useremo:
- GitHub per il repository
- Git Bash come terminale
- il server studenti della scuola come web server
Creare l'account su GitHub
Per prima cosa andate su sito di GitHub e, se non l'avete già fatto, create un account. Ovviamente scegliete il piano gratuito, è più che sufficiente per i nostri scopi.
Scaricare Git Bash
Su Windows, si consiglia di usare Git Bash come terminale, scaricabile da qui.
Durante l'installazione potete premere sempre "Next", come se non ci fosse un domani.
Se nei computer di scuola dovesse chiedervi la password da amministratore, tornate all'inizio, deselezionate la spunta in basso "Show only new options", e quando vi fa scegliere la cartella di installazione selezionate la vostra cartella home. Quindi premete sempre avanti, alla fine vi chiederà comunque la password da amministratore ma anche se premete "Cancel" procederà comunque all'installazione. Attenzione che se vi trovate in questa situazione, vi dovrete ricordare di specificare il percorso git alle varie applicazioni che ne fanno uso (per esempio Visual Studio Code).
Dopo averlo installato, apritelo, vi compare un simpatico schermo nero: siete pronti a cominciare la vostra avventura da programmatori.
Se avete un computer Apple o Linux, non avete bisogno di installare nulla perché c'è già un terminale integrato. Con Apple, se volete potete scaricare iTerm, che ha più funzionalità del terminale integrato.
Accesso al web server
Prima di tutto, vi serve sapere il vostro nome utente. Il nome utente è composto da:
- una lettera assegnata dal professore alla classe, per esempio nel vostro caso è la lettera
c _utente- due numeri che identificano la vostra posizione in rubrica, ad esempio
01,12, etc.
Un nome utente valido è ad esempio c_utente26
Dal terminale, digitate:
ssh nome_utente@studenti.marconicloud.it
Digitate la password. Anche se non la vedete per motivi di sicurezza, la legge ugualmente, abbiate fede.
In questo modo avete fatto l'accesso alla vostra cartella sul serve studenti.
Creazione del repository su GitHub
Sulla pagina di GitHub del vostro account, cliccate sul + in alto a destra e premete su New repository.
Mettete le seguenti cose:
- nome:
error503 - descrizione:
TPSI 2021 - lasciate su Public
- cliccate su Add README.md
- cliccate su Add License e selezionate GNU oppure MIT.
Sulla pagina che vi compare, andate sul bottoncione verde "Code", quindi copiate il link del repository.
Clonazione del progetto sul web server
Tornate sul terminale, controllate di stare sul server remoto (il prompt dei comandi deve mostrare @serverStudenti), quindi scrivete:
git clone https://........
Dove https://....... è il link che avete appena copiato. Vi creerà una cartella nel punto in cui vi trovate chiamata error503. Entrateci dentro:
cd error503
Ora create il vostro primo file index.html usando il comando nano:
nano index.html
Modifica del progetto
Il progetto grafico della nostra pagina web è il seguente:

In questa pagina possiamo vedere che ci sono solo due elementi: un titolo con sotto un paragrafo. Per il titolo, possiamo usare il tag h1, mentre per il paragrafo il tag p.
La pagina verrà come segue:
<h1>503 Service Unavailable</h1>
<p>No server is available to handle this request.</p>
Mi raccomando controllate che sia la correttezza delle parole e la capitalizzazione delle lettere (maiuscole e minuscole). In questa fase, dal punto di vista visivo dovete solo riportare fedelmente quanto previsto dal progetto grafico, senza inventare o modificare nulla.
Dopo aver salvato il file, controllate che la pagina sia corretta andando dal browser sul link: https://studenti.marconicloud.it/nome_utente/error503, facendo ovviamente attenzione a sostituire nome_utente con il vostro nome utente.
Se è tutto OK, potete passare alla parte di sincronizzazione delle modifiche con GitHub.
Sincronizzare le modifiche
Per prima cosa, dobbiamo dire a git che effettivamente vogliamo sincronizzare il file index.html. Questo si fa con git add:
git add index.html
Quindi, dobbiamo confermare che siamo proprio sicuri di voler salvare in modo permanente le modifiche all'interno del nostro repository. Questo si fa con git commit:
git commit
La prima volta che vi trovate su un nuovo computer, vi chiederà chi siete. Seguite le informazioni su schermo, quindi ripetete il commit.
Vi si aprirà nuovamente nano, chiedendovi di mettere un commento per il commit. I commenti cominciano sempre con un verbo, quindi potete mettere "Aggiunto index.html". Salvate ed uscite da nano.
Ci siamo quasi! Le modifiche fatte finora sono solo in locale, non sono ancora sincronizzate con il server remoto di GitHub; questa operazione si chiama push. Prima di poter fare il push però, GitHub richiede che venga generato un token di autorizzazione; infatti da agosto 2021 non è più possibile usare la password per motivi di sicurezza.
Andate su github.com, cliccate in alto a destra sull'immagine del vostro account e scegliete "Settings" nel menù a tendina che si apre. Andate nella barra a sinistra su "Developers settings", quindi su Personal access tokens. In alto a destra premete su "Generate new token".
Mettete le seguenti informazioni:
- note: Server studenti marconi
- expiration: 90 giorni
- scopes: selezionate "repo", si selezionano automaticamente anche le caselle al suo interno
Ora in fondo alla pagina premete su "Generate token".
Vi verrà visualizzato un token, non chiudete questa pagina che fra poco vi serve e se chiudete la pagina non potrete più recuperarlo!
Tornate sul terminale. Diciamo a git di salvarsi le credenziali che stiamo per inserire, in modo da non doverle ripetere ogni volta:
git config --global credential.helper store
Ora siamo finalmente pronti per fare il push!
git push
Vi chiederà nome utente e password. Attenzione che come password dovete inserire il token che abbiamo generato poco fa.
Finalmente, è fatta! Se tutto è andato bene potrete vedere la vostra pagina index.html anche su GitHub.
Video tutorial per la creazione di un progetto su GitHub
Di seguito le stesse operazioni per la creazione di un progetto su GitHub in un video tutorial. Il progetto nel video si chiama error404, ma le operazioni sono le stesse.
Sintassi HTML
Dopo essersi riscaldati un po' con un "splash project", vediamo di razionalizzare ed assimilare correttamente quello che abbiamo fatto.
Una pagina HTML è formata da un insieme di elementi. Prendiamo ad esempio il titolo.
<h1>Error 503</h1>
Tutto insieme questo è chiamato elemento.
Scomponiamo questo elemento nelle sue parti.
<h1>: tag di aperturaError 503: contenuto</h1>: tag di chiusura
Attributi
Un elemento può avere uno o più attributi, ad esempio:
<a href="demo.html">questo è un link</a>
Gli attributi servono per specificare caratteristiche dell'elemento a cui si riferiscono. Ad esempio, l'attributo src serve per specificare il percorso dell'immagine da visualizzare.
Ogni attributo consiste di un nome ed un valore separati da un =. Il valore può essere senza apici se non contiene nessun carattere speciale o spazio, altrimenti deve avere apici singoli o doppi. In ogni caso, per convenzione, si preferisce mettere sempre gli apici intorno al valore degli attributi.
Alcuni attributi possono non avere nessun valore, come nell'esempio successivo. In questo caso si parla di attributi booleani.
<input name="address" disabled>
Void elements
Alcuni elementi possono non avere un contenuto, come nel caso seguente.
<img src="logo.png">
Gli elementi senza contenuto non hanno un tag di chiusura. Questo tipo di elementi si chiama void element. Al link precedente trovate la lista esatta di quali elementi sono void.
Nota: HTML5 non richiede nessuna sintassi particolare per chiudere gli elementi void. Per retro-compatibilità con le precedenti versioni di HTML, comunque, è permesso chiudere il tag anche con '/>'
Elementi annidati
Gli elementi possono essere annidati fra loro.
<p><span>Hello World</span></p>
Qui possiamo vedere che:
<span>Hello World</span>è il contenuto dell'elemento con tag<p>(paragrafo)Hello Worldè il contenuto dell'elementospan
Non può mai succedere invece che gli elementi si intersechino fra di loro, come nell'esempio che segue.
<p><span>Questo è mooolto sbagliato!</p></span>
Doctype, head, body
La pagina error404 che abbiamo scritto finora funziona, ma manca di alcune informazioni importanti che aiutano il browser a visualizzare correttamente il contenuto della pagina web. Vediamoli ora nel dettaglio.
Doctype declaration
Tutte le pagine HTML devono cominciare con una "dichiarazione" (declaration) che dice esplicitamente al browser che quella che sta leggendo è effettivamente una pagina HTML. Il browser prova ad indovinarlo dall'estensione, ma è richiesto che lo si scriva esplicitamente, per evitare errori.
<!DOCTYPE html>
Questa dichiarazione è simile ad un tag, ma con l'aggiunta di un punto esclamativo subito dopo la parentesi angolare aperta. Questa strategia di usare un punto esclamativo (bang nel dialetto geek) per specificare il tipo di file è molto usata nei linguaggi di programmazione, e la vedrete anche negli script per la shell.
Tag <html>
Come abbiamo detto nel capitolo precedente, la struttura di una pagina HTML è come un albero, che parte da un tronco. Questo tronco è rappresentato dal tag <html>.
<html>
</html>
Il tag html ha l'attributo "lang" che è importante specificare per permettere al browser di capire in che lingua è scritta la pagina, ad esempio italiano, inglese, cinese, etc.
<html lang="it">
</html>
Dal tag html si dipartono due rami: <head> e <body>.
Tag <head>
Il tag <head> contiene tutti i metadati. I metadati sono dei dati che riguardano la pagina, ma non vengono visualizzati direttamente all'interno di essa. Vediamo i più importanti:
<meta charset="UTF-8">: specifica la codifica dei caratteri; in generale sarà sempre UTF-8 (unicode)<meta name="viewport" content="width=device-width, initial-scale=1.0">: rende il sito responsive, ovvero capace di adattare il contenuto alle dimensioni dello schermo<title>Document</title>: specifica il titolo della pagina, che ad esempio nei browser viene visualizzato all'interno del tab in alto
Altri metadati che possono essere inclusi nel tag <head> sono ad esempio lo stile e, in alcuni casi, gli script.
Tag <body>
All'interno del tag body troviamo tutti gli elementi che verranno effettivamente renderizzati all'interno della nostra pagina: intestazioni, paragrafi, immagini, suoni, video, barre di navigazione, sezioni, etc. etc.
CSS
L'HTML è fin da subito nato come uno standard aperto: questo all'inizio ha creato delle difficoltà, ma con il passare del tempo si è rivelato un aspetto vincente.
![]()
La definizione del CSS è un tipico esempio di quanto detto. Nei primi anni di diffusione (1993-1996) le aziende che crearono i primi browser (Netscape e Internet Explorer in particolare) aggiunsero diverse estensioni proprietarie dell'HTML, generando confusione e difficoltà per gli sviluppatori di pagine web. In altre parole, ciò che funzionava su un browser non funzionava su un altro. Il W3C decise di affrontare questo problema creando un gruppo di lavoro che produsse uno standard nel 1996 chiamato appunto Cascading Style Sheet (CSS).
Per maggiori dettagli sulla storia del CSS si rimanda a questa pagina.
Con il passare degli anni, questa divisione si rivelò estremamente efficace. In particolare, riuscì in modo eccellente a risolvere il problema della diversa dimensione degli schermi dei palmari prima e degli smartphone poi.
CSS include moltissime funzionalità che permette l'animazione degli elementi nelle pagine, le trasformazioni (es. traslazione, rotazione, scalatura), i gradienti e molte altre cose.
Concetti base
Sintassi
Cominciamo con la sintassi e la nomenclatura dei vari componenti di un foglio di stile.
Un foglio di stile CSS è formato da un insieme di regole. Ogni regola ha la seguente struttura:

Vediamola nel dettaglio.
- la regola comincia con un selettore, che serve per selezionare su quali elementi verrà applicata la regola
- la seconda parte della regola è la dichiarazione, racchiusa in parentesi graffe
- all'interno della dichiarazione c'è una lista di proprietà, separate da punto e virgola
- ogni proprietà ha un nome ed un valore, separati tra loro dai due punti
Vediamo alcuni esempi:
/* cambia il colore dello sfondo di tutta la pagina */
body {
background-color: blue;
}
/* cambia il colore del testo di tutti i paragrafi */
p {
color: red;
}
Di seguito dettagliamo alcune caratteristiche importanti del CSS.
Specificità
Come detto, CSS è l'acronimo di "Cascading Style Sheet", che si può tradurre come "fogli di stile a cascata". Questo perché è del tutto lecito includere più fogli di stile, o avere più regole all'interno dello stesso foglio di stile, che si riferiscono allo stesso elemento.
Tutte le regole che si potrebbero applicare ad un certo elemento, si chiamano matching rules e si dice che queste regole entrano in competizione tra di loro. Quale vince?
La risposta è: la regola con specificità più alta per quel determinato elemento. Il calcolo della specificità non è banale, ma per ora ci basta sapere che, a parità di altre condizioni, viene applicata la regola definita per ultima.
Elementi inline e block
Un altro concetto fondamentale del CSS è che un elemento può essere di uno di questi due tipi:
- inline: si adatta al contenuto
- block: si adatta al contenitore
Alcuni elementi sono nativamente inline, ed altri nativamente block.
Ad esempio, i paragrafi sono block e gli span sono inline:
<style>
p {
background-color: red;
}
span {
background-color: blue;
}
</style>
<p><span>ciao</span></p>
Questo è il risultato:

Quando nella scrittura della pagina mi servono alcuni elementi inline o block per agganciarli al CSS ma senza un particolare valore semantico, posso usare i seguenti tag:
<span>come generico elemento inline<div>come generico elemento block
In ogni caso, è sempre possibile cambiare il comportamento di default di un elemento attraverso la proprietà CSS "display":
/* la seguente regola trasforma i paragrafi in elementi inline */
p {
display: inline;
}
Nota: esiste anche un valore ibrido inline-block, utile in alcune situazioni, per maggiori informazioni vedete qui
Box model
L'ultimo concetto CSS che presentiamo in questo pagina è il modello a scatole, in inglese "box model".
Come abbiamo detto, possiamo immaginare la nostra pagina come tante scatole. Come è fatta ognuna di queste scatole?
Ogni scatola è composta delle seguenti parti:
- il contenuto vero e proprio, ad esempio il testo, l'immagine o altri elementi annidati, che vogliamo visualizzare
- il padding: l'imballaggio, sta all'interno della nostra scatola, quindi coprirà anche l'eventuale colore o immagine di sfondo
- il border: la confezione, ovvero il rettangolo che include padding e contenuto
- il margin: il margine tra una scatola e l'altra

Contenuto

Padding

Bordo

Margine
Per visualizzare il box model nel browser, andate su ispeziona, ve lo trovate tra i pannelli sviluppatore
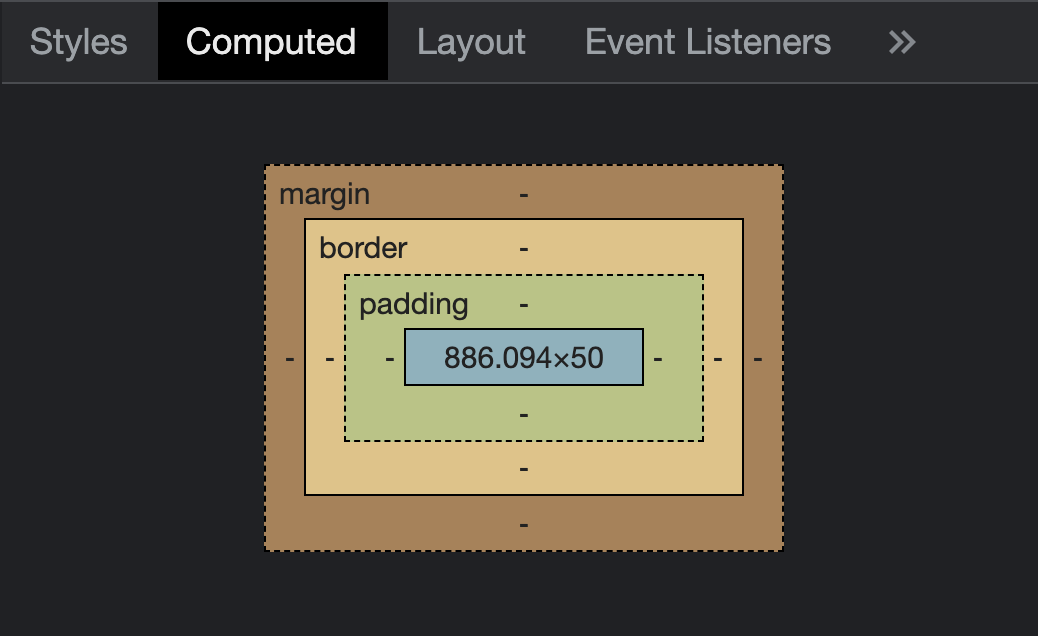
Fate attenzione che, generalmente, i margini tra due elementi si sommano: se un elemento ha margine destro pari a 10px, e il successivo ha margine sinistro pari a 15px, il margine totale tra i due elementi sarà 25px.
A questa regola generale ci sono alcune eccezioni. Ad esempio, se ci sono più elementi figli con lo stesso tag, i margini superiore ed inferiore possono collassare tra loro. Per maggiori informazioni, vedete qui.
Impostare i valori del box model
Per impostare i valori del box model esistono le seguenti proprietà CSS:
padding: per impostare il paddingborder: per impostare il bordomargin: per impostare il margine
Esempi
Nel seguente esempio imposto i valori in tutte e quattro le direzioni intorno all'elemento selezionato.p {
padding: 5px;
border: 0px;
margin: 5px;
}
Di solito voglio però controllare in modo più fine il valore in una specifica direzione, ad esempio solo in alto, o solo a sinistra. Per fare questo, ognuna di queste proprietà ha a sua volta quattro sotto proprietà:
-top: sopra l'elemento-right: a sinistra dell'elemento-bottom: a destra dell'elemento-left: a sinistra dell'elemento
Esempi
Nel seguente esempio imposto i valori solo nelle direzioni scelte.p {
padding-left: 5px;
border-top: 0px;
border-bottom: 0px;
margin-right: 5px;
}
Se voglio impostare tutti e quattro i valori per una data proprietà in un colpo solo, esiste una versione abbreviata, in cui specifico tutti i valori nella stessa linea. Mi devo ricordare che i valori sono messi come i numeri di un orologio analogico: parto dall'alto e giro in senso orario, quindi nell'ordine sono top, right, bottom, left.
Esempi
Nel seguente esempio imposto tutti e quattro i valori in una sola linea.p {
background-color: red;
padding: 0px 15px 30px 50px;
}
Il risultato:
ciao
Centrare un elemento orizzontalmente
Per centrare un elemento orizzontalmente, possiamo usare la proprietà margin con valore auto.
p { margin:auto;}
Cosa significa esattamente? Il browser calcola la dimensione del paragrafo, la dimensione del suo contenitore, e imposta i margini a destra e sinistra in modo che siano uguali. Ricordiamo però che, per gli elementi block, la dimensione dell'elemento è esattamente pari a quella del contenitore, quindi verranno impostati entrambi i margini a zero. Per evitare questo, possiamo impostare la dimensione dell'elemento che vogliamo centrare con width:
p {
margin:auto;
width: 50%;
background-color: gray;
}
Risultato:
Buongiorno a tutti!
Attenzione: in questo caso l'elemento è centrato (come vedete dal colore di sfondo) ma non il testo al suo interno. Per centrare anche il testo all'interno dell'elemento, dobbiamo usare la proprietà text-align:center.
p {
/* ... */
text-align: center;
}
Buongiorno a tutti!
Ci sono molti altri modi per centrare un elemento orizzontalmente e verticalmente. Per una carrellata piuttosto esaustiva si rimanda qui.
Dove metto il tag style?
Lo stile è considerato un metadato, quindi come tutti i metadati la documentazione ufficiale richiede di metterlo all'interno del tag <head>, di solito subito prima del tag di chiusura.
<head>
<!-- altri metadati qui -->
<style>
/* mettere qui lo stile */
<style>
</head>
Ci sono altri modi per includere un foglio di stile salvato come un file .css a sé stante, li vedremo successivamente.
Selettori
Finora nei selettori abbiamo utilizzato solo il nome del tag. In questo modo, abbiamo selezionato tutti i tag con quel nome nella pagina.
Di solito però vogliamo essere più precisi, selezionando solo alcuni elementi. Per fare questo il CSS mette a disposizione due attributi: id e class.
Attributo id
Si usa l'attributo id quando voglio selezionare un elemento unico nella pagina. Ad esempio, se tra tutte le immagini presenti nella pagina voglio selezionare quella relativa all'avatar (unica all'interno della pagina), potrei scrivere:
<img id="avatar" src="myavatar.png">
Per selezionare l'elemento con un certo id, si usa la notazione con il cancelletto '#' (si pronuncia hash, in inglese).
#avatar {
width: 10%;
}
Attributo class
Si usa class quando vogliamo individuare più elementi che hanno una caratteristica comune. Ad esempio, se voglio selezionare tutti i pulsanti all'interno della mia pagina che devono essere di colore verde, potrei scrivere:
<button class="btn-green" >...</button>
Per selezionare tutti gli elementi con una certa classe, si usa la notazione con il punto '.' (si pronuncia dot, in inglese).
.btn-green {
background-color: green;
}
Selettore universale
Per selezionare tutti gli elementi della pagina, esiste il selettore universale (universal selector), che si rappresenta con l'asterisco * (star, in inglese).
# Cambia il font di tutti gli elementi della pagina in Times New Roman.
* {
font-style: font-family: "Times New Roman", Times, serif;
}
Combinare i selettori fra loro
I selettori visti finora possono essere combinati tra loro per selezionare in maniera ancora più precisa. Questo è spesso utile se non si vogliono o non si possono aggiungere classi e id all'HTML.
Di seguito alcuni modi più comuni per combinare. Per la lista completa, come al solito si rimanda alla pagina dedicata su w3schools.
Combinazione semplice
Il modo più semplice di combinare i selettori è scrivere un tag seguito dalla classe, senza spazi. Ad esempio se voglio selezionare tutti i paragrafi con la classe green:
p.green {}
Se voglio invece mettere più selettori insieme, posso separarli da virgola. Ad esempio se voglio selezionare tutti i titoli h1 e h2:
h1, h2 {}
Discendente
Posso selezionare tutti gli elementi discendenti di un elemento, mettendo semplicemente uno spazio. Per discendenti si intende figli, nipoti, pro-nipoti, etc.
Per selezionare solo i paragrafi all'interno dell'elemento con id pari a news:
#news p {}
Figlio
Per selezionare solo gli elementi che sono figli diretti di un altro elemento uso il simbolo >:
Per esempio se voglio selezionare solo i paragrafi immediatamente dentro #news (e non i paragrafi all'interno di altri sotto-elementi), posso scrivere:
#news > p {}
Classi, id o combinatori: quali usare?
Spesso ci si chiede: meglio aggiungere una classe o un id agli elementi che voglio selezionare, oppure trovarli con un combinatore?
Come al solito, dipende, non c'è una risposta univoca. Alcune domande potrebbero essere:
- qual è il modo più semplice?
- come potrebbe cambiare il codice della pagina in futuro?
- qual è la specificità della regola?
L'esperienza in questi casi è fondamentale. Quindi... esercitatevi!
Specificità dei selettori
I selettori hanno ognuno una propria specificità. Di seguito sono elencati dalla specificità più bassa alla più alta:
- Tag (es.
h1) - Classi (es.
.btn-green) - ID (es.
#avatar)
In altre parole, come intuibile, le regole selezionate con l'ID avranno la precedenza sulle altre, seguite da quelle selezionate con le classi e poi dai generici tag. Il selettore universale ha specificità nulla (più bassa di tutte).
Ad esempio, ipotizziamo di avere il seguente paragrafo:
<p id="esempio" class="esempio">Ciao</p>
con il seguente CSS:
#esempio {
background-color: red;
}
p {
background-color: blue;
}
.esempio {
background-color: green;
}
Quale colore assumerà il paragrafo? La regola con l'ID ha la specificità più alta e verrà quindi applicata:
Ciao
In caso di selettori combinati fra loro, esiste una formula per calcolare la specificità, si rimanda qui per maggiori dettagli.
Per vedere tutte le regole applicate ad un certo elemento potete usare i devTools di Chrome o Firefox; trovate le regole nel tab "style". Per indagare possibili conflitti tra regole, c'è questa guida ufficiale di Chrome.
Riepilogo
Ricapitolando, i selettori di base sono di 3 tipi:
- tag: non hanno nessun prefisso, selezionano tutti gli elementi con il tag selezionato. Ad esempio
div {background-color:red}colora di rosso lo sfondo di tutti gli elementi con il tag div - id: ha come prefisso
#(cancelletto), seleziona l'elemento che ha come attributo id il valore specificato. Ad esempio#my-title {font-weight:bold}rende grassetto l'elemento che ha come attributoid="my-title" - class: ha come prefisso
.(punto), seleziona tutti gli elementi che hanno come attributo il valore specificato. Ad esempio.small-images {width=5%}imposta la larghezza di tutti gli elementi che hanno come attributoclass="small-imagesal 5% della larghezza dello schermo.
Esistono molti altri modi di selezionare gli elementi, ma si basano tutti su questi concetti base. Per maggiori informazioni potete consultare questa pagina.
Unità e colori
Unità di misura
Nelle dichiarazioni CSS, ci sono molti modi di specificare le dimensioni sullo schermo. Ne vediamo alcune fra le più comuni. Per maggiori dettagli vedi qui.
Pixels (px)
Il modo più semplice è specificare il numero di pixels:
p {
margin-top: 50px;
}
Questa unità può essere adatta per fissare degli elementi nello schermo, come ad esempio bottoni fluttuanti, o per specificare la distanza tra elementi vicini. Però non è responsive: al cambiare della dimensione dello schermo la distanza rimane sempre la stessa, e questo spesso non è quello che vogliamo.
Percentuale (%)
Si può impostare la dimensione come percentuale dell'elemento contenitore. Ad esempio, se voglio che il mio paragrafo occupi il 50% della dimensione del proprio contenitore, posso scrivere:
p {
width: 50%;
}
Relativo alla dimensione del testo (rem)
In molti casi può essere utile avere delle dimensioni che si adattano alla grandezza del testo; in questo caso si usa rem:
/* La dimensione del testo di questo paragrafo è il doppio rispetto a quella base. */
p.big {
font-size: 2rem;
}
Le dimensioni relative al testo sono molto utili anche perché scalano automaticamente quando si ingrandisce o rimpicciolisce il testo della pagina.
Colori
Per scegliere un colore, abbiamo diverse possibilità.
Nome del colore
Possiamo scegliere un colore usando il nome della paletta CSS.
p {
background-color: lightgreen;
}
Potete vedere la lista completa dei colori supportata dalla maggior parte dei browser qui.
RGB
Un altro modo è specificare le componenti RGB:
p {
background-color: rgb(200,200,200);
}
Questo è particolarmente utile quando si usa ad esempio il color-picker per prendere un colore dallo schermo o da una immagine.
Hex
Un altro modo molto usato nel web design, è usare l'RGB ma con valori esadecimali anziché decimali. Le tre cifre RGB in esadecimale si scrivono una di seguito all'altra, senza spazi, precedute da un cancelletto #.
p {
background-color: #0000FF;
}
Ricordiamo che un byte esadecimale va da 00 (spento) a FF (255-tutto acceso).
La conversione tra RGB decimale ed esadecimale è un semplice calcolo matematico, quindi è una questione di comodità e preferenze.
Per convertire tra decimale ed esadecimale, potete usare questo.
Il sistema operativo
In questo capitolo impareremo le basi del sistema operativo Linux e dell'uso del terminale.
Organizzazione di un sistema operativo
Il sistema operativo (OS) gestisce le risorse della macchina (memoria, processore, periferiche) per diversi scopi, principalmente:
- astrae il funzionamento dello specifico hardware (es. un particolare monitor o hard-disk), fornendo un'interfaccia comune per gli sviluppatori
- permette a più applicazioni di poter funzionare contemporaneamente, condividendo il processore e la RAM
- evita conflitti nella gestione concorrente delle risorse
Ma ogni cosa ha un suo costo: il sistema operativo utilizza per sé stesso una porzione a volte considerevole delle risorse del nostro computer: pensiamo a quanti GB sul disco occupa una installazione di Windows o Mac, a quanta memoria occupa, alla percentuale di CPU impegnata. Oltre a questo esistono problemi di vulnerabilità, aggiornamento, etc.
Se vogliamo far girare un solo programma su un certa macchina (per esempio Arduino), possiamo anche non usare un sistema operativo. Tipicamente questo accade per piccoli elaboratori che devono svolgere compiti molto specifici: questo sistemi vengono chiamati embedded e hanno al loro interno un processore chiamato microcontrollore (mentre i sistemi operativi girano su macchine con microprocessori).
Il sistema operativo è una componente software molto complessa: per poter essere gestita in maniera ottimale, è stata divisa in sotto-componenti. Di seguito vediamo i principali.
Kernel
Per rappresentare i componenti del sistema operativo, si usa spesso la metafora "a guscio", o delle sfere concentriche, in cui al centro di tutto c'è l'hardware.

Il programma che è più vicino all'hardware viene chiamato kernel. Noi ci occuperemo in particolare del kernel Linux, un kernel open-source.
Il kernel Linux è stato creato nel 1991 dal finlandese Linus Torvalds ed è distribuito attraverso la licenza di software libero GNU GPLv2. Questa licenza è stata ideata da Richard Stallman (vedi sotto). Linus Torvalds è celebre anche per aver realizzato il software git e per avere un carattere schietto e scontroso.

Il kernel è la parte dell'OS che si occupa di mediare l'accesso delle applicazioni alle risorse del computer:
- central processing unit (CPU)
- memoria volatile (RAM)
- periferiche di input/output (hard disk, tastiera, mouse, stampanti, etc.)
Il kernel è un programma come gli altri, non ha niente di "magico". In particolare il kernel è un insieme di librerie scritte principalmente in C/C++. Del kernel Linux possiamo anche vederne il codice sorgente, visto che è un software libero e quindi anche aperto.
Shell
Per usare direttamente il kernel dovremmo scrivere dei programmi in C/C++, ad esempio per interrogare l'hard-disk e farci restituire i file all'interno di una certa cartella. Scrivere un programma per ogni operazione che dobbiamo svolgere però non è molto comodo.
Per poter usare in maniera semplice le chiamate di sistema che ci mette a disposizione il kernel esistono una serie di strumenti che ci facilitano i compito. Per Linux, queste utilità sono state sviluppate dal progetto GNU, e si chiamano GNU coreutils.
Il progetto GNU è stato fondato nel 1983 da Richard Stallman, al MIT di Boston. GNU ha lo scopo in primo luogo di permettere agli sviluppatori di tutto il mondo di poter sviluppare liberamente software, ovvero avendo a disposizione il codice sorgente dei programmi di altre aziende che usano, e senza la necessità di pagare licenze. Le utilità che useremo in questo corso sono solo parte del progetto; un'altra parte fondamentale è la licenza che permette al software di essere usato legalmente, rispettando le libertà fondamentali del free software. Il nome di questa licenza è GPL (General Public Licence), di cui l'ultima versione è la GPLv3


Anche in questo caso possiamo andare a cercare il codice sorgente. Non ci deve stupire che in questo caso il repository non sia su GitHub, perché è un prodotto Microsoft, mentre GNU utilizza solo software 100% open e free.
Terminale
Per poter interagire con la shell, abbiamo bisogno di un'applicazione specifica che ci permetta di farlo. Quest'applicazione si chiama "terminale".

Nell'immagine vedete l'applicazione "iTerm2", molto usata in ambito Apple come terminale. Per Windows, consiglio di usare git bash.
Risorse esterne
Si consiglia la lettura di questo PDF con una introduzione a Linux e all'open-source.
Uso della shell
Apriamo il nostro terminale e cominciamo a prendere confidenza con le varie componenti.
Prompt dei comandi
Appena aperto il terminale, notiamo che compare subito una stringa di testo che ci dà varie informazioni. Questa stringa si chiama prompt dei comandi, o semplicemente prompt.

Di solito il prompt contiene:
- il nome dell'utente corrente
- il nome della macchina su cui ci troviamo
- la cartella in cui ci troviamo
- il simbolo $ oppure % che precede il cursore di inserimento
L'interprete dei comandi
Dopo il prompt possiamo inserire il nostro comando, ad esempio per visualizzare i file nella cartella corrente, possiamo usare ls.

Vediamo cosa è successo dietro le quinte:
- la stringa che scriviamo, in questo caso
ls, viene passata all'interprete dei comandi, ovvero la "shell" vera e propria - la shell interpreta il comando e fa le chiamate di sistema necessarie al kernel
- ritorna su schermo l'output del comando
Comando, argomenti e opzioni
Il comando vero e proprio è sempre la parola che viene scritta subito dopo il prompt. Un comando può opzionalmente essere seguito da degli argomenti, separati da spazi.
Ad esempio, ls nomefile mostra solo il file specificato nell'argomento.

Se l'argomento comincia con un trattino, prende il nome di opzione. Un'opzione serve per modificare il funzionamento del comando in qualche modo.
Ad esempio, l'opzione -l del comando ls mostra più dettagli sui file.

Un'opzione che comincia con un singolo trattino (-) è detta "short option" e l'opzione stessa è un singolo carattere, ad esempio -l. Un'opzione che comincia con due trattini (--) e detta "long option" ed è una parola intera, ad esempio --version.
Attenzione: tra il comando e le opzioni ci deve essere uno spazio. Se scrivete ls-l, questo verrà interpretato tutto insieme come il nome di un comando.
Informazioni su un comando
Per visualizzare le informazioni relative ad un comando, in base al sistema che usate potete usare una delle seguenti strategie:
$ man nomecomando # apre una finestra nel prompt con i dettagli, per uscire premere q
$ nomecomando --help # stampa direttamente sul terminale i dettagli
Normalmente si usa la prima modalità, ma git bash usa la seconda.
Variabili
Con la shell si possono usare le variabili. Il terminale mette a disposizione un certo numero di variabili di ambiente, che vengono definite ogni volta che viene aperta una nuova finestra.
Tutte le variabili, quando sono richiamate, devono essere precedute dal simbolo del dollaro ($).
Per visualizzare il valore della variabile, possiamo usare il comando echo. Ad esempio, esiste una variabile d'ambiente si chiama SHELL e contiene il percorso al programma della shell stessa.
$ echo $SHELL
/usr/bin/bash
Se richiamo la variabile senza dollaro, non viene interpretata correttamente:
$ echo SHELL
SHELL
Notate anche che la shell è case sensitive:
$ echo $shell
Come vedete, se provo a stampare una variabile che non esiste, mi ritorna una stringa vuota.
Altre variabili di ambiente utili sono:
$ echo $TERM # mostra lo standard seguito dal terminale in uso
xterm
$ echo $PROMPT # mostra il prompt corrente
%F{green}%n%f@%F{magenta}%m%f %F{blue}%B%~%b%f %#
Per visualizzare tutte le variabili di ambiente, potete usare il comando env.
Gestione dei permessi
Risorse esterne
Scripting
In questo capitolo vedremo come creare dei semplici script.
Molti dei concetti di cui parlerò qui sono trattati anche nella guida più autorevole sullo scripting in bash, l'Advanced Bash Scripting Guide (ENG, ITA). Come sempre, si suggerisce la consultazione in lingua originale, per evitare problemi di traduzione.
Cos'è uno script?
Uno script è un programma che non viene compilato, come siamo abitutati a fare con linguaggi come C, C++ o Java, ma viene interpretato riga per riga da un altro programma, detto appunto interprete. Nel nostro caso, l'inteprete è la shell stessa.
Per chiarire meglio il concetto con un esempio:
- un file
.cppdeve essere compilato in un file .exe, che poi può girare su tutte le macchine compatibili. Il file .cpp originale non dobbiamo distribuirlo agli utenti finali. - un file
.shdeve essere distribuito così com'é agli utenti che lo dovranno utilizzare, che lo eseguiranno direttamente.
Scelta dell'interpete
Di default, uno script viene interpretato con l'inteprete che si usa in quel momento per lanciare lo script stesso. È possibile cambiare questo comportamento specificando l'interprete da usare nella prima riga dello script, iniziando la riga con #!, ad esempio per usare python invece che bash, si può scrivere:
#!/usr/bin/env python3
La combinazione di caratteri #! viene chiamata anche shebang, che sta per "shell bang" o shabang, che sta per "sharp bang", dai nomi in dialetto nerd dei caratteri che sono appunto rispettivamente sharp per il cancelleto e bang per il punto esclamativo.
Creazione di uno script di esempio: cleanup.sh
Di seguito uno script di esempio creato a lezione, che illustra alcuni concetti chiave.
# Cleanup
DIR=$1
cd $DIR
cat /dev/null > messages
cat /dev/null > tmp
echo "Log files cleaned up."
exit 0
Analizziamo il file riga per riga.
# Cleanup
Tutte le righe che cominciano con un cancelletto sono commenti.
DIR=$1
In questa riga dichiariamo la variabile DIR e gli assegniamo il valore del primo parametro in ingresso allo script. Per esempio, se lanciamo lo script con cleanup.sh temp il valore di DIR sarà temp. Osservazioni importanti:
- intorno all'
=non devono esserci spazi, altrimenti la riga non viene valutata come un'assegnazione ma come un comando normale. - nella dichiarazione, la nuova variabile non deve essere preceduta dal dollaro.
cd $DIR
Mi sposto nella cartella $DIR. Attenzione che quando uso una variabile, deve essere sempre preceduta dal dollaro.
cat /dev/null > messages
cat /dev/null > tmp
Creo i file vuoti messages e tmp oppure, se già esistono, li svuoto.
echo "Log files cleaned up."
Stampo su console l'informazione che ho eseguito il cleanup.
exit 0
Esco dall'applicazione. Se questa riga viene messa alla fine del file, l'interprete uscirebbe comunque dall'applicazione, ma è buona pratica uscire sempre esplicitamente con exit, specificando come argomento il valore di ritorno dello script.
Negli script bash, il valore di ritorno
0vuol dire "tutto OK", mentre valor di ritorno diversi da zero di solito significano un errore. Per leggere il valore di ritorno dell'ultimo comando eseguito, si può utilizzare$?sia da terminale che all'interno di uno script.
Allegati
In questa sezione trovate alcuni allegati utili.
Comandi linux
echo
Ritorna un'"eco" del suo argomento sul terminale.
$ echo ciao
ciao
touch
Crea un file o, se già esiste, ne aggiorna la data di ultima modifica.
$ touch ciao
cat
Abbreviazione di "concatenate", mostra il contenuto di un file.
$ cat ciao
Redirect
Il carattere > redirige l'output di un comando verso un file, invece del terminale. Se il file non esiste, viene creato. Se il file esiste, viene sovrascritto.
$ echo "buongiorno" > buongiorno.txt
Se si vuole aggiungere il testo alla fine del file senza sovrascriverlo, si può usare il >>.
$ echo "buongiorno" >> buongiorno.txt
$ cat buongiorno.txt
buongiorno
buongiorno
ls
Elenca i file nella cartella corrente
$ ls
buongiorno.txt ciao
L'opzione -l mostra i dettagli del file.
$ ls -l
total 8
-rw-r--r-- 1 claudio staff 11 Oct 12 07:03 buongiorno.txt
-rw-r--r-- 1 claudio staff 0 Oct 12 07:00 ciao
Aggiungendo anche l'opzione -h mostra i dettagli del file in un formato più leggibile per l'essere umano ("human"). Notare la B alla fine della quinta colonna, che sta per "Byte".
$ ls -lh
total 8
total 8
-rw-r--r-- 1 claudio staff 11B Oct 12 07:03 buongiorno.txt
-rw-r--r-- 1 claudio staff 0B Oct 12 07:00 ciao
Un'altra opzione utile è -a, per visualizzare anche i file nascosti. Su linux, un file è nascosto semplicemente se inizia con il carattere punto (.).
$ ls -lha
total 8
drwxr-xr-x 4 claudio staff 128B Oct 12 07:03 .
drwxr-xr-x 4 claudio staff 128B Oct 12 07:00 ..
-rw-r--r-- 1 claudio staff 11B Oct 12 07:03 buongiorno.txt
-rw-r--r-- 1 claudio staff 0B Oct 12 07:00 ciao
pwd
Abbreviazione di Print Working Directory, visualizza la directory corrente.
$ pwd
/Users/claudio/try/bash
mkdir
Abbreviazione di "make directory", crea una nuova cartella.
$ mkdir food
$ ls -l
-rw-r--r-- 1 claudio staff 22 Oct 12 07:12 buongiorno.txt
-rw-r--r-- 1 claudio staff 0 Oct 12 07:00 ciao
drwxr-xr-x 2 claudio staff 64 Oct 12 07:14 food
Si può capire che è una cartella perché il primo carattere nella riga di "food" è una d che sta appunto per "directory". I file hanno invece un trattino. Alcuni terminali mostrano le cartelle anche con un colore diverso.
cd
Abbreviazione di "change directory", permette di spostarsi tra cartelle.
$ cd food
$ pwd
/Users/claudio/try/bash/food
Usando cd senza argomenti, torno alla "home directory", che viene anche rappresentata con il simbolo ~ (si legge tilde).
$ cd
$ pwd
/Users/claudio/
$ cd ~ # comando equivalente al precedente
$ pwd
/Users/claudio/
Per tornare alla directory precedente, si può usare il simbolo - (trattino).
$ cd -
$ pwd
/Users/claudio/try/bash/food
Per salire di una directory si può usare il doppio punto.
$ cd ..
$ pwd
/Users/claudio/try/bash
cp
Copia un file, abbreviazione di copy.
$ cp ciao hello
$ ls
total 8
-rw-r--r-- 1 claudio staff 22 Oct 12 07:12 buongiorno.txt
-rw-r--r-- 1 claudio staff 0 Oct 12 07:00 ciao
drwxr-xr-x 2 claudio staff 64 Oct 12 07:14 food
-rw-r--r-- 1 claudio staff 0 Oct 12 07:20 hello
mv
Sposta un file da una cartella ad un'altra cartella.
# Sposta il file "ciao" dalla cartella corrente alla cartella "food"
$ ls -l
-rw-r--r-- 1 claudio staff 22 Oct 12 07:12 buongiorno.txt
-rw-r--r-- 1 claudio staff 0 Oct 12 07:00 ciao
drwxr-xr-x 2 claudio staff 64 Oct 12 07:14 food
-rw-r--r-- 1 claudio staff 0 Oct 12 07:20 hello
$ mv ciao food
$ ls -l
-rw-r--r-- 1 claudio staff 22 Oct 12 07:12 buongiorno.txt
drwxr-xr-x 2 claudio staff 64 Oct 12 07:14 food
-rw-r--r-- 1 claudio staff 0 Oct 12 07:20 hello
$ ls -l food
-rw-r--r-- 1 claudio staff 0 Oct 12 07:00 ciao
Se la cartella di partenza e destinazione coincidono, semplicemente rinomina il file.
# Rinomina il file "hello" in "hola"
$ mv hello hola
$ ls -l
-rw-r--r-- 1 claudio staff 22 Oct 12 07:12 buongiorno.txt
drwxr-xr-x 2 claudio staff 64 Oct 12 07:14 food
-rw-r--r-- 1 claudio staff 0 Oct 12 07:20 hola
rm
Elimina un file, abbreviazione di remove.
$ rm hola
$ ls
-rw-r--r-- 1 claudio staff 22 Oct 12 07:12 buongiorno.txt
-rw-r--r-- 1 claudio staff 0 Oct 12 07:00 ciao
drwxr-xr-x 2 claudio staff 64 Oct 12 07:14 food
ctrl-c
Termina (uccide) il processo corrente.
Variabili di ambiente
Ogni terminale usa delle variabili che sono definite automaticamente quando viene aperto. Queste variabili vengono dette variabili di ambiente. Per visualizzarle si può usare il comando env.
$ env
TERM_SESSION_ID=w1t0p0:3B371076-0F20-4C26-ACD4-4656F13F9AEA
SSH_AUTH_SOCK=/private/tmp/com.apple.launchd.P5eh4I2m5h/Listeners
LC_TERMINAL_VERSION=3.4.10
COLORFGBG=7;0
......continua.......
Per visualizzare una sola variabile, si può usare echo e la variabile deve essere preceduta dal carattere dollaro.
$ echo $SHELL
/bin/bash
Per assegnare una variabile, si può usare il comando export.
$ export PS1="test>"
Di seguito alcune variabili di ambiente che abbiamo visto:
- $TERM: quale standard rispetta l'applicazione terminale in uso, di solito è
xtermoxterm-256color - $SHELL: quale shell sto utilizzando, su Ubuntu di default è bash (quella sviluppata da GNU)
- $PS1: il prompt dei comandi, ovvero tutto quello che c'è prima del dollaro (dollaro compreso), solitamente include la directory corrente ed il nome utente
SSH
Per collegarsi via ssh alla macchina remota, da terminale potete digitare:
$ ssh nome_utente@server
Ad esempio
$ ssh c_utenteNN@studenti.marconicloud.it
Se, dopo il primo accesso, volete tornare a questo comando senza doverlo ridigitare, potete:
- premere freccetta su, fino ad arrivare al comando
- digitare
ctrl-re cominciare a digitare il comando, per eseguire una ricerca nello storico dei comandi
Uso del file .ssh/config
Se si vuole aggiungere in modo stabile il server remoto ai propri preferiti, è possibile aggiungerlo al file .ssh/config.
Per fare questo, aprite un terminale e scrivete:
$ cd # per tornare alla home directory
$ cd .ssh # per entrare nella cartella nascosta .ssh
$ nano config
A questo punto aggiungete al file le seguenti righe:
Host marconi
HostName studenti.marconicloud.it
User k_utenteNN
Da ora in poi per collegarvi al server, potete digitare semplicemente:
ssh marconi
Extra: utenti sulla macchina
who
Per sapere gli utenti loggati sulla macchina su cui gira il terminale, con relativo pseudo-terminale, data di ultimo login e, in caso di accesso da remoto, indirizzo IP da cui ci si connette.
c_utente00@serverStudenti:~$ who
c_utente00 pts/0 2022-05-12 08:53 (10.13.0.20)
b_utente00 pts/1 2022-05-12 08:53 (10.13.0.20)
write
È un comando generalmente poco usato ma è installato di default in tutte le distribuzioni, serve per comunicare tra utenti.
c_utente00@serverStudenti:~$ write b_utente00
Ciao come va?
# ctrl-d
c_utente00@serverStudenti:~$
Per uscire dal comando write, premere la combinazione di tasti ctrl-d.
HTML template
Di seguito un template per una pagina .html vuota.
<!DOCTYPE html>
<html lang="it">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
</body>
</html>
Questo è il template generato da Visual Studio Code, quando create un nuovo file con estensione .html e premete il punto esclamativo nel file vuoto.
Git reference
Potete trovare una guida scritta da me qui.
Operazioni comuni
Per aggiungere un file:
git add nomefile
Per committare i file aggiunti:
git commit
e scrivere un messaggio di commit, che deve iniziare con un verbo.
Per inviare le modifiche locali al server remoto (GitHub):
git push
Per prendere le modifiche dal server remoto e portarle nel computer locali:
git pull